The Dark Side of AI, AI Patents & AI Index Report -- 🦛 💌 Hippogram #7
The 7th edition of the Hippogram focuses on AI patents and open access to knowledge.

Welcome to our newsletter for health and tech professionals - the weekly Hippogram.
I'm Bart de Witte, and I've been part of the health technology community and industry for more than 20 years as a social entrepreneur. In that time, the evolution of technologies changed the face of healthcare, business models and culture in many inspiring but unexpected ways.
This newsletter wants to share knowledge and insights. This is the heart of the Hippo AI Foundation, named after Hippocrates. Know-How will increasingly result from our data, so it's crucial to share it in our digital health systems. We believe that building more equitable and sustainable global digital health will benefit everyone.
I'm thrilled that Hippogram is getting recommended by our readers and that we have readers from 12 different countries. Want to read the whole newsletter? Sign up here for the entire Hippo experience.
Patents, Patents everywhere but not a single drop drink
The recently published 2022 AI Index Report by Stanford Institute for Human-Centered Artificial Intelligence showed that the number of patent applications in 2021 would be more than 30 times higher than in 2015, with a compound annual growth rate of 76.9%.
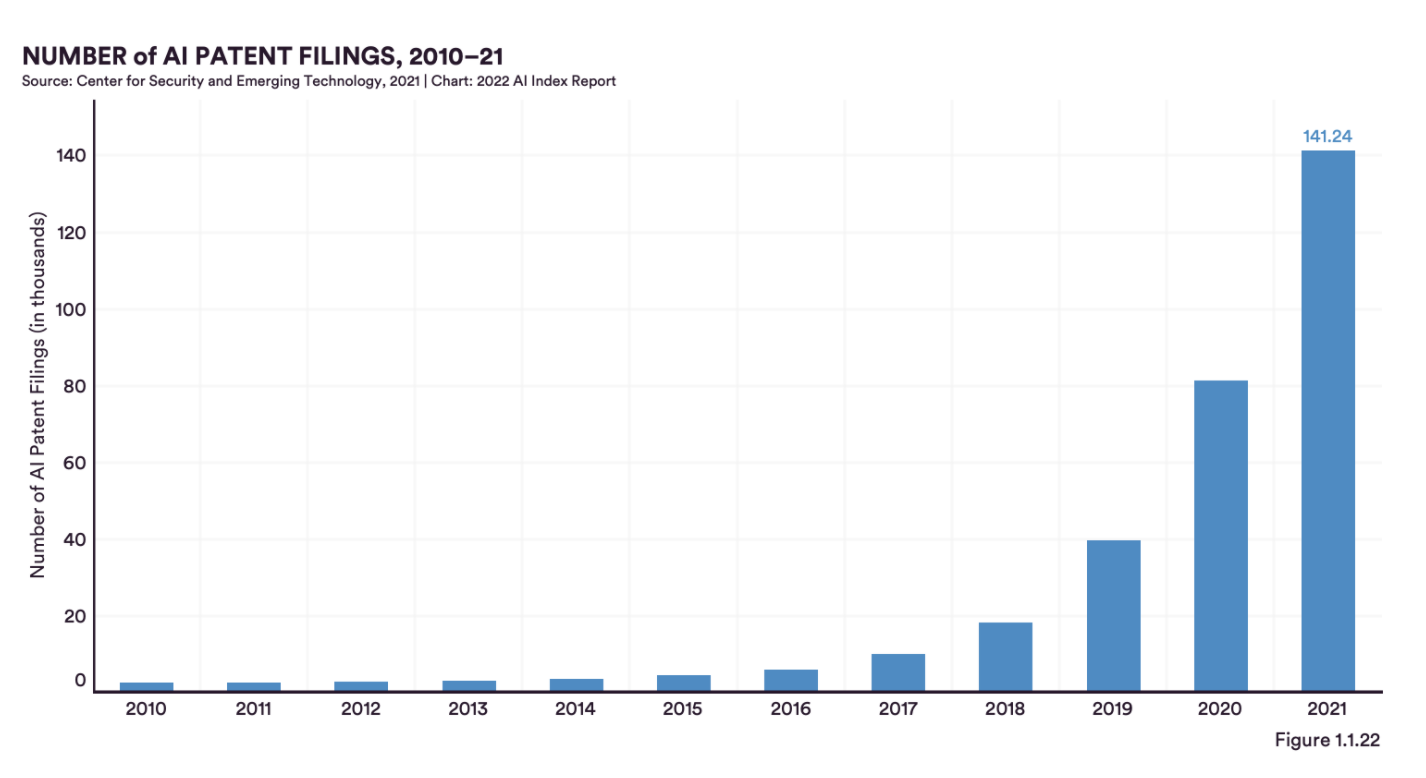
This exponential increase means that the solution to demand more transparency is further away than ever before. Why? Keeping their AI models hidden will lower the risk of patent infringements, something we could witness in the Netflix mini-series The Billion Dollar Code, where Joachim Sauter, a media artist who helped develop "Terra Vision" in the early 1990s and who actually went to court against Google. This rapid increase in AI patents filings will be causing more difficulties than it is solving. Let me explain;
Power Asymmetries and the dark age of AI
In 2020 a Berlin-based NGO called, AlgorithmWatch launched a project to monitor Meta's Instagram newsfeed algorithm. Only by understanding how society is affected by platforms' algorithmic decisions can we take action to ensure they don't undermine us. Undermine our autonomy, freedom, and common good. Volunteers could install a browser add-on that scraped their newsfeeds. Data was sent to a database used to study how Instagram prioritizes pictures and videos in a user's timeline. From the collected data, the research team wanted to understand which images and videos are being favoured by the algorithms of Meta. In spring 2021, Meta threatened AlgorithmWatch with legal action if the company continued its data donation project. Algorithmwatch reported that Meta had accused it of violating its terms of use, prohibiting the automatic collection of data. Faced with Facebook's threat to take "more formal action," the NGO terminated the project.
Understanding the workings of algorithmic decisions is a fundamental difficulty in implementing algorithms. The so-called black boxes make this tough. The black box issue within the AI industry mostly refers to the “technical black box”. The prevalence of this issue has driven research towards developing explainable AI. The field of explainable AI is concerned with how AI models arrive at their results. The intention is to provide visibility into how an AI system makes decisions and predictions and executes its actions. It surfaces the strengths and weaknesses of the process and gives a sense of how the system will behave in the future without having to deliver the source code not publish the training data.
But as the case of AlgorithmWatch versus Meta demonstrates, the central issue of understanding algorithmic decision making might not be the technical black box, but what is described in the literature as the so-called "legal black box". The term "legal black box" refers to the opacity that arises from the fact that it is proprietary software. To put it another way, algorithms and data are frequently treated as trade secrets. The legal black box is primarily based on intellectual property rights (trade secrets, database rights, etc.). The data transmitted from users and devices to client servers and the cloud is heavily protected by intellectual property rights.
Despite the fact that there are numerous open-source machine learning frameworks, most AI algorithms are proprietary (Google search and Facebook news feed are two famous examples), which means they are protected mostly by trade secrets, the most frequent type of company protection.
These trade secrets prevented the Google Health research team from publishing the details, including a description of model development and the data processing and training pipelines used, for their AI model trained on over 90,000 mammography X-rays. Google published in January 2020 a paper, and claimed that it outperformed human radiologists. The compnay withheld the definitions of many hyperparameters for the architecture of the model (variables used by the model to make diagnostic predictions), as well as the variables used to augment the dataset on which the model was trained.
Secrets make bad science
Later that year Nature released a critical rebuttal written by 31 experts to a Google Health report published earlier this year in the magazine. Science is based on a foundation of trust, and peer review, which in general means disclosing enough information about how the research was conducted so that others can replicate it and verify the results for themselves. In this way, science self-corrects and weeds out results that do not stand up to scrutiny. Replication also allows others to extend those results, furthering the advancement of the field. Science that cannot be duplicated is discarded.
Last month, the European Commission proposed a new Data Act, a new flagship piece of legislation aimed at "making the EU a leader in a data-driven society." The new EU legislation establishes a number of new guidelines for businesses on when, how, and with whom they should disclose data. The proposal, among other things, establishes data access and portability regulations for data created by business users and people while using a service and depends on parties' good intentions to avoid unfair competition and the disclosure of trade secrets.
Last year, the European Commission released its proposal for an Artificial Intelligence Regulation, the AI Act. In 2024, the AI Act is predicted to pass. It continues the prior policy direction of AI transparency by including various clear criteria. However, the exact definition of transparency is still unknown. Transparency is required for interpretability, but it also implies that many types and degrees of transparency exist. The AI Act does not define what exactly the interpretability of AI’s outcome is.
So the question we all need to ask is why proven concepts within the Science community are being challenged with new concepts that focus on building walls around life-saving algorithms that are trained on patient data?
In a recent paper in the Lancet called „Bridging the chasm between AI and clinical implementation“, Eric Topol mentions that progress is likely to come with the development of open-source AI trained on open data depositories and publicly shared algorithms.
Currently, it feels like intellectual property lawyers, policymakers, and lobbyists are determining the future of health. I live in Berlin, and everyone here knows that building walls is never a good idea. I hope AI policymakers start focusing more on open-source AI for healthcare, as that is the only way to create true transparency and trust. Legal black boxes are tools that disempower civil society and patients and set the stage for a system designed around information and power asymmetries, ultimately leading to health inequities.
Technology Inspired Art
In the artwork Accomplice, artificially intelligent robots gradually destroy a wall.
It explores the concept of machine autonomy and aims to remind the audience that society not only depends on technology but is shaped by it too. Read more

Support Data Solidarity & AI Commons
Bart de Witte: Our European healthcare systems are based on the principle of solidarity, which is the reason why I think citizens need to push for #datasolidarity - if we humans share - companies should share as well - that is the only principle on how we can avoid information asymmetries that lead to power asymmetries which will be the base for inequalities in health.
#OpenThinker Of The Week

Lukas is a researcher and developer focusing on magnetic resonance imaging. As the founder of opensourceimaging.org, he aims to make medical devices available globally.
The Open Source Imaging Initiative (OSI²) aims to make the healthcare benefits of modern tools accessible to many more people by building a quality, affordable open-source magnetic resonance imaging scanner.
On a global scale, only a few regions have sufficient access to MRI services, and the cost of ownership is immense. Access is further hampered by expensive service contracts that require costly maintenance and training.
Medical imaging is critical for both the diagnosis and treatment of many diseases. MRI provides a detailed view of internal tissues without the need to perform invasive procedures or damage to the body and is thus a helpful tool to diagnose diseases. Increased availability, accessibility and affordability of this essential technology improve and save lives.
That's where opensourceimaging.org comes in. The project began in 2016 and brought together the knowledge and experience of more than 100 experts in open-source magnetic resonance imaging (MRI) and other sciences. Their designs can be built and maintained at a fraction of the price of current equipment. The project team envisions that developers from research institutions or industries will be able to download all files necessary to assemble and operate these MRI scanners locally. The access to information furthermore allows an easier repair through in-house technicians in hospitals or third-party service providers, guaranteeing that the systems are not only available but also functional where they are needed.
In an open-source model, where the expertise of a large community can be accessed, it is envisioned to substantially reduce the total cost of ownership of these systems. In addition to the lower costs for the equipment and its maintenance, there are further advantages: Unrestricted access to knowledge is made possible, global collaboration is accelerated, and education around this technology. Instead of a small team of developers, an international community works on further development and optimization.
Thank you for reading the Hippogram. I'll be back next week; until then, stay well and best wishes.
Bart.
Share Your Feedback
Was it useful? Help us to improve!
With your feedback, we can improve the letter. Click on a link to vote:
About Bart de Witte & the Hippo AI Foundation
Bart de Witte is a leading and distinguished expert for digital transformation in healthcare in Europe but also one of the most progressive thought leaders in his field. He focuses on developing alternative strategies for creating a more desirable future for the post-modern world and all of us. With his Co-Founder, Viktoria Prantauer, he founded the non-profit organisation Hippo AI Foundation, located in Berlin.
The Hippo AI Foundation is a non-profit that accelerates the development of open-sourced medical AI by creating data and AI commons (e.q. data and AI as digital common goods/ open-source). As a charitable data trust for data altruism, the organization unites, cleanses, and de-identifies data from individual and institutional data donations. This means data that is made available without reward for open-source usage that benefits communities or society at large, such as the use of breast-cancer data to improve global access to breast cancer diagnostics.