Bridging the Digital Divide: Harnessing Copyleft for Equitable AI Innovation -- 🦛 💌 Hippogram #25

During the last few years, I have been calling for copyleft licensing for health data. Now, with my latest article, I delve into how copyleft licenses can dismantle information asymmetries, accelerate innovation, and make healthcare advancements accessible to all. By ensuring that data derivatives remain open and public, we can protect patient interests, democratize AI, and foster a more equitable digital future. Dive into the full article to explore how we can leverage copyleft licensing to transform the healthcare landscape.
The digital divide & accessible and inclusive innovation
The digital divide is a chasm that's widening by the day, fueled by the assetization of data and the rise of artificial intelligence. A handful of Leviathans are hoovering up the world's data, using it to build AI systems that are as opaque as they are powerful. This creates a toxic feedback loop where the rich get richer, and the poor get poorer - a Matthew Effect that's suffocating innovation and entrenching inequality.
The recent surge in the open-source AI movement has demonstrated a powerful counter-narrative. The cost savings of open-source AI are astounding, with estimates suggesting it can be up to 50 times more affordable than proprietary AI. Moreover, open-source AI has the potential to enable decentralized systems that prioritize user privacy, which in healthcare is an absolute game changer. It's not surprising, then, that large corporations and would-be monopolies like OpenAI or Anthropic AI have been working to suppress open-source AI innovations. They've been spreading unfounded fears about the risks of open-source AI, including the threat of bioterrorism, claims that have been thoroughly discredited as pseudoscience or propaganda. The open source movement challenges these traditional proprietary models by promoting transparency, collaboration, and inclusivity in technological advancements.
We need to celebrate these open-source achievements, as they have done more to prevent monopolies and promote a culture of openness and shared innovation than many regulatory measures. For example, Google's search market share in Europe was over 90% before the introduction of GDPR, and it remains at being over 90% five years after GDPR was implemented. Recent surveys from the Linux Foundation and Andreessen Horowitz have shown that the majority of surveyed companies prefer open-source AI that is on par with closed-source alternatives.
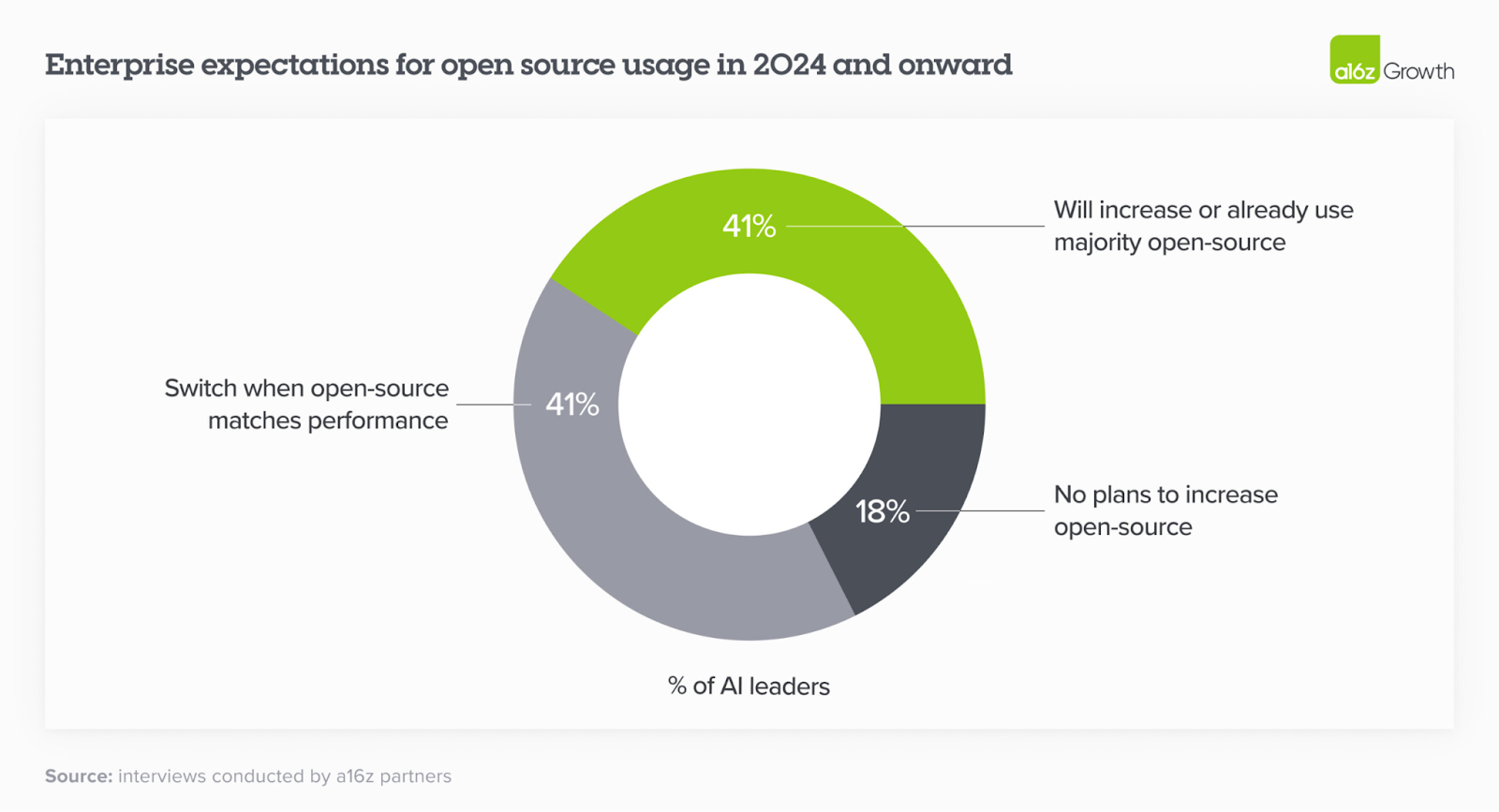
This indicates that open-source large language models (LLMs) are becoming the new industry standard and is going through a phase of commoditization. In terms of equality of opportunity, open source allows researchers and innovators in low-income countries to build AI-based solutions without needing a credit card to feed the API of companies like Google or OpenAI. This accessibility is crucial for democratizing technology and ensuring that the benefits of AI advancements are available to all, regardless of economic status. This shift underscores the effectiveness of the open-source movement in setting new benchmarks for innovation and accessibility in the AI industry, fostering an environment where everyone can contribute to and benefit from technological progress.
Policies
Despite these benefits, current policies often prioritize short-term gains through technology transfers from academia to private industry. Such policies fail to differentiate between research leading to proprietary knowledge and research generating open, public knowledge. Consequently, patient data intended to advance public health is frequently used to develop closed systems and patented technologies, reinforcing the very asymmetries these policies aim to mitigate.
In healthcare, certain policies have exacerbated this trend, favoring larger, capital-rich corporates over fostering open ecosystems. These policies often prioritize commercial interests and the rapid monetization of research outputs, giving a significant advantage to well-funded entities that can navigate and influence regulatory landscapes. This has stifled smaller innovators and public-interest projects, limiting the diversity and accessibility of medical advancements.
Copyleft Licensing
Copyleft licensing offers a robust solution to these challenges. By requiring that any adaptations or derivatives of the original work remain under the same open terms, copyleft licenses ensure that innovations stemming from patient data cannot be monopolized. This approach dismantles information asymmetries by guaranteeing that knowledge remains accessible and shared, accelerating innovation in the process.
The paper "Generative AI and Creative Commons Licences: The Application of Share Alike Obligations to Trained Models, Curated Datasets and AI Output" by Kacper Szkalej and Martin Senftleben highlights how copyleft licenses can be effectively applied in the AI domain. The authors argue that Share Alike (SA) obligations found in Creative Commons (CC) licenses can be extended to trained AI models, curated datasets, and AI-generated outputs. This extension ensures that any AI developments using copyleft-licensed data adhere to the same open principles, thus preserving the commons and preventing exclusive control.
By using copyleft licenses, we can prevent the Matthew Effect—where the rich get richer and the poor get poorer—and avoid the paradox of openness, where open resources are exploited without reciprocation. Copyleft creates a legally enforceable framework that mandates the continued openness of derivative works, fostering an environment where innovation thrives and is accessible to all. Applied to health data, this would be an absolute game changer.
To make digital healthcare systems sustainable and prevent our medical knowledge from being owned by a few AI companies on the West Coast of California, we need policies that allow patients to choose. In the last few years, I have conducted several surveys and found that over 85% of participants prefer that the data derivatives created from our patient data remain accessible to everyone, all while preserving full privacy. There was one interesting outlier in the survey: a director for innovation of the German Ministry of Health, who was still stuck with the old narrative that only closed knowledge would lead to innovation. When reading such hyperbolic claims, I always ask myself in which bubble they have been hiding.
These findings underscore the public's preference for open, non-proprietary use of their data, highlighting the need for policy shifts that prioritize long-term public benefits over short-term gains from, sometimes exclusive technology transfers to private industry.
The European Health Data Space
However, this approach is not in the interest of investors who have short-term transactions in mind and profit from market consolidation through mergers and acquisitions that lead to new potential monopolies. Such investors typically favor proprietary systems that can be tightly controlled and monetized, perpetuating information asymmetries and concentrating power in the hands of a few. In addition to investors, I have also noticed in recent years that some academic hospitals aim to leverage the European Health Data Space (EHDS) to financially gain from the data we consented for. This trend further underscores the necessity of adopting copyleft licensing and patient choice to ensure that medical data and its derivatives remain a public resource, promoting equitable access and preventing the commercialization of data that patients generously provided for the common good. By embracing these measures, we can help democratize access to medical knowledge and ensure that innovations benefit the many rather than the few.
Conclusion
In conclusion, copyleft licensing has the potential to transform how patient data is used in research, ensuring that the resulting innovations serve the common good and startups and SME's rather than following the interests of a few global big corporates. By embedding these principles in the AI development process, we can accelerate technological advancements, promote equity, and ensure that the benefits of innovation are shared widely across society.