Sea, Shift and Open -- 🦛 💌 Hippogram #13

I'm Bart de Witte, and I've been inside the health technology industry for more than 20 years as a social entrepreneur. During that time, I've witnessed and was part of the evolution of technologies that are changing the face of healthcare, business models, and culture in unexpected ways.
This newsletter is intended to share knowledge and insights about building a more equitable and sustainable global digital health. Sharing knowledge is also what Hippo AI Foundation, named after Hippocrates, focuses on, and it is an essential part of a modern Hippocratic oath. Know-How will increasingly result from the data we produce, so it's crucial to share it in our digital health systems.
Welcome to our newsletter for health and tech professionals - the bi-weekly Hippogram.
Fake Democratised AI
It will not be DALLE 2, PaLM, AlphaZero, LaMDA, or even GPT-3 that will advance humanity, nor will those who establish paywalls to prohibit free access to massive data sets have the utmost socioeconomic impact over the next decade. If history teaches us anything, it are those individuals who tear down barriers and work in the open that will become catalysts for positive change and create AI that benefits all of mankind.
OpenAI
Benefiting all mankind was the initial pledge of OpenAI Inc, a non-profit AI research and deployment business. The firm was formed by Elon Musk, Sam Altman, and others, who pledged a total of $1 billion. In 2019, OpenAI Inc revealed that it was unable to raise the funds required to realize its aims and establish OpenAI LP as a for-profit. Microsoft invested $1 billion a few months following the transition. The relationship between OpenAI and Microsoft was formed based on letting the latter commercialise a portion of the technology, as we've seen with GPT-3 and Codex. Although OpenAI's effort has yielded respectable results, these results were inconsistent with its claim to be "democratizing" AI. Their claims of openness are a hoax as none of their AI has been publicly sourced.
When OpenAI switched from a non-profit to a for-profit organization and revealed its exclusive relationship with Microsoft, open-source skeptics felt validated in their belief that altruistic and open-source research doesn't work and only closed developments do, because these developments depend on large investments that need an immediate return on investment (ROI).
When I hear people questioning open-source development, I always wonder where they've been for the past 20 years as open source has been around. In the last 20 years, technology companies that want to lead the market have been actively supporting and taking part in community-driven projects that work on open-source developments. Open source is not an artefact, and it is part of the research and development strategy of every tech company.
A megatrend is born
When I made the statement a few years ago that open-sourced AI will be the only way to move forward in order to improve mankind as a whole and boost Europe's competitiveness, very few people in my immediate context understood what I meant. Today, I still can not understand that it didn't become part of the EU's strategy, especially in the area of health care.
However, over the past several months, we have been able to see a phenomenal acceleration in the development of open-source AI. In a recent Hippogram, I honored Joelle Pineau, the director of Meta AI Research Labs, as the open innovator of the week. Pineau was the driving force behind Meta AI's decision to grant open access to Meta's OPT-175B large language model (LLM). In order to access Meta's model, one must first submit a request, and the license only permits its utilization for research reasons. Before the release of OPT-175B, the only open-sourced transformer model that was available was GPT-NeoX-20B. This model was developed by EleutherAI in collaboration with Connor Leahy, who works for Aleph Alpha in Heidelberg, Germany.
Bloom
I've always wondered why Meta, the company that threatened Algorithm Watch for trying to shed some light on Instagram's dark algorithms, suddenly became more open. Joelle was probably well aware of the activities of the BigScience BLOOM Project, and she had no choice but to open up. We could witness similar movements with Alpafold who published their model as open source, after RoseTTAFold published theirs as open source.
Now, only a month later, Meta’s OPT-175B Is meta's work is overshadowed by an open source project called BLOOM (BigScience Language Open-science Open-access Multilingual). BLOOM is the name of a recently published open-source version of a LLM that was developed by a worldwide collective (BigScience Alliance) effort with 1000 academic volunteers from 250 different countries. This work marked the group's entry into the field of huge language models.
Open Source Training Data
Open Source AI Model
Open Source methods and documents
New Copyleft License
Data Governance via local communities
BLOOM opens the black box not just of the model itself but also on the process through which LLMs are developed and the participants who are eligible to take part in it. The BigScience team has given communities outside of big tech the ability to develop, criticize, and manage an LLM by making its progress publicly recorded and extending an open invitation to any interested participants and users. Local requirements have been taken into account by BigScience by means of regional working groups. These groups expand the concept of model localization beyond the simple addition of a language to include context-specific decision-making and assessment. The training data includes over 59 different languages, 13 of which are programming languages.This is a huge step forward for the open source community and truly democratises AI research.
Bloom has 175 billion parameters and received support from the CNRS, GENCI, and the French Ministry of Higher Education and Research, allowing BLOOM to be trained on the Jean Zay French supercomputer. Kudos to the French Goverment for supporting this effort.
Big Science Real License
Because the BigScience Team knows what LLMs can do and wish to promote responsible development and use of LLMs, they made a Responsible AI License ("RAIL") for the model's use in the broadest sense of the word. With this type of license, the model can be used in commercial applications, but there are some restrictions. The RAIL license was made so that it can be used for licensing terms of any derivative versions of any of the BigScience BLOOM models that a downstream user offers or releases. In other words, the RAIL-license could be compared to the so-called "copyleft" clause of the GPL family of licenses. This means that any Derivatives of the Model (as defined in the license) should be subject to the same use-based restrictions. The concept of a Responsible AI License ermerged from a community effort to give developers the power to limit how their AI technology can be used through end user license agreements and source code license agreements.
It is a very similar mode to the model that I have designed for the HIPPO AI Foundation, with the difference that the HIPPO AI License is a Data and Model license and connects health data with AI models. We did not publish it yet, as we lack the resources to do so.
For example, you are not allowed to use the model;

Data Governance
Bloom also open sourced and presented a strategy for the governance of data, to train a Large Language Model. This will further accelerate the democratisation! The Protocols for reaching distinct ideals, working with existing norms, and grappling with varied rules that are relevant across datasets were critical components of the governance system.
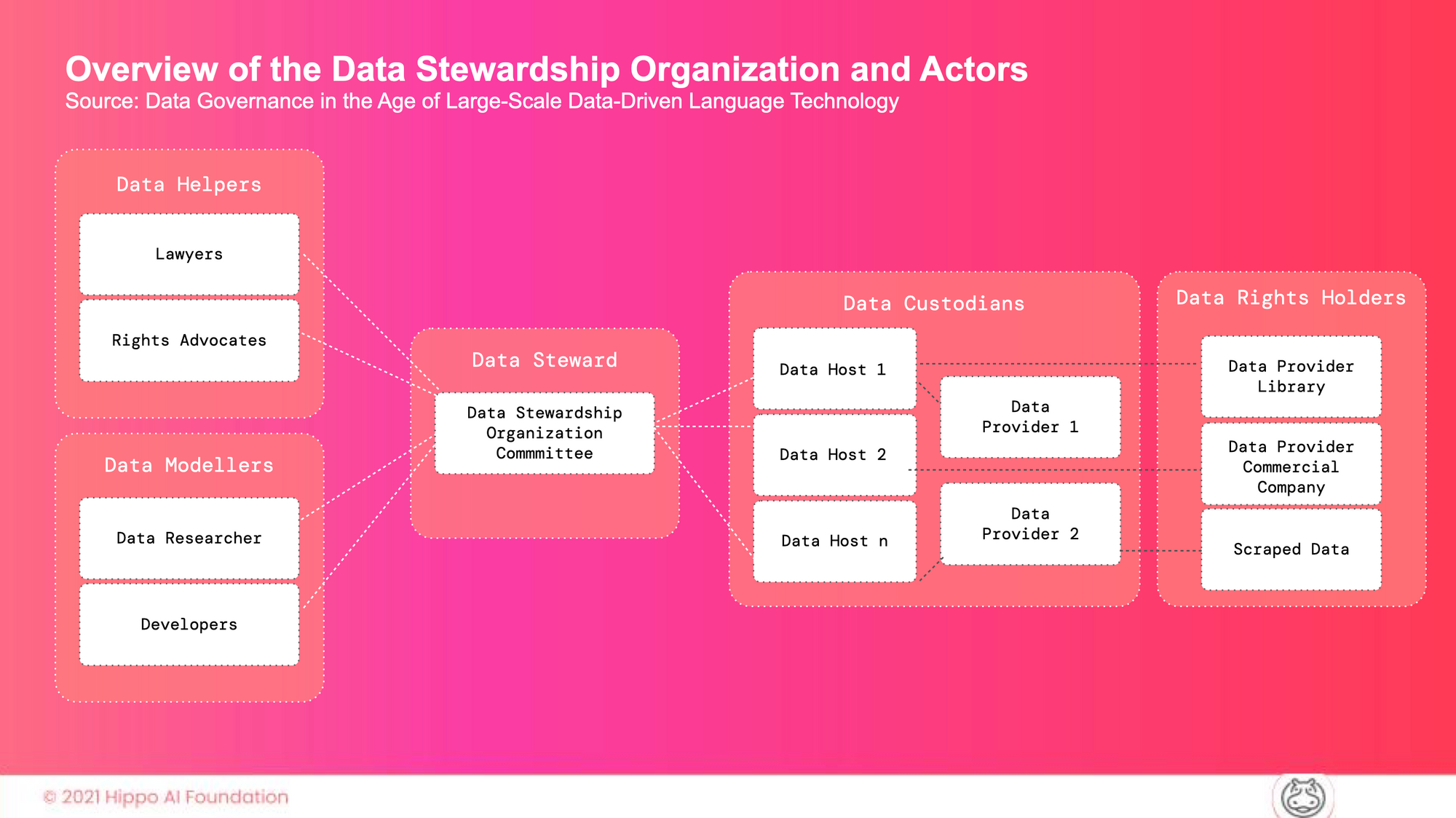
This was an immense effort to coordinate the number of different rights-holders and stakeholders. Their method connects data providers, data hosts, and data developers. A Data Stewardship Organization is in charge of coordinating this process. This organization is also responsible for developing proper management plans, access controls, and legal scholarship.
In order to collect data, the project's data chair recruited communities of native speakers. They handpicked more than 60 percent of the 341 billion-word data set that was used to train the AI. The communities chose content that was true to their languages and cultures. This method, in which people are asked to organize 60% of the training data, is a big change. Still 40% of the BigScience data set comes from a normal crawl of the internet. BigScience made an effort to avoid making value judgements about the sexual nature of the crawled internet data, and when it came time to filter the data, they erred on the side of not banning keywords.
Collaboration Benefiting all mankind
A sea shift is coming to the world of artificial intelligence, and Bloom is leading the charge. Those who believe that human collaboration only occurs when individuals are working toward the creation of intellectual property assets have been given a smack in the face. Academics can also see this as a useful opportunity to be reminded that not all innovations deserve to be commercialized through the process of transferring technology.
I am inclined to agree with those people who argued that Bloom is the most important AI model of the decade. Perhaps it was not so much because of the AI model itself, but rather because everything that has been disclosed is meant to be replicated. This endeavor is the antidote to major monopolistic capital driven innovations that have locked up their systems, and it blooms the establishment of an open AI ecosystem.
It puts a significant amount of pressure not just on the several BigTech, but also on the startup companies and their investors that have been operating with an closed AI objective. This huge open-source project will inspire more people to work together. And hardly any organization would be able to hire tjhe ampount of people to do the opposite. It will cross-polinate to industry specific AI developments such as healthcare, where current regulations (European Health Data Space) and funding are moving in the other direction.
Bart's Favourite Stories
Topics You Need To Know About
Exponential Acceleration: we’re Training AI Twice as Fast This Year as Last
According to the best measures we’ve got, a set of benchmarks called MLPerf, machine-learning systems can be trained nearly twice as quickly as they could last year. It’s a figure that outstrips Moore’s Law, but is also one we’ve come to expect. Most of the gain is thanks to software and systems innovations, but this year also gave the first peek at what some new processors, notably from Graphcore and Intel subsidiary Habana Labs, can do.
History of Open: IBM's Open Architecture
Not many people that work in the digital health industry have deep insights into the history of computing. Open sourced architectures for example were responsible for the PC boom in the 90s. IBM‘s idea to use an open access architecture allowed them to reduce R&D costs but also to expand the eco-system by allowing others to copy their architecture. While open, IBM was in control, so it was more an ego-system than an eco-system. But Open source has evolved, and collaboration models are more based on consensus and survival of the fittest.
This strategy stands in hard contrast with the closed world of AI in healthcare. In this new world, every single company is training their models to do the same as their competitors are doing. Each is fighting for more data and exclusivity, which given the fact that also digital healthcare needs to be based on golden standardised models doesn‘t make sense. The current philosophy increases the R&D cost and slows down adoption as physicians do not like black boxes. During the last few years, I learned that the main driver for these closed models is based on short-term financial goals that focus on the valuation when exiting the company. IMHO these short-term goals do not align well with the overall promise of AI in healthcare.
Was it useful? Help us to improve!
With your feedback, we can improve the letter. Click on a link to vote:
About Bart de Witte
Bart de Witte is a leading and distinguished expert for digital transformation in healthcare in Europe but also one of the most progressive thought leaders in his field. He focuses on developing alternative strategies for creating a more desirable future for the post-modern world and all of us. With his Co-Founder, Viktoria Prantauer, he founded the non-profit organisation Hippo AI Foundation, located in Berlin.
About Hippo AI Foundation
The Hippo AI Foundation is a non-profit that accelerates the development of open-sourced medical AI by creating data and AI commons (e.q. data and AI as digital common goods/ open-source). As an altruistic "data trustee", Hippo unites, cleanses, and de-identifies data from individual and institutional data donations. This means data that is made available without reward for open-source usage that benefits communities or society at large, such as the use of breast-cancer data to improve global access to breast cancer diagnostics.